OpenClaw : un agent LLM sur votre infrastructure
OpenClaw connecte un agent LLM à votre infrastructure. Comparaison avec N8N, capacités, et surface d'attaque : ce que vous ouvrez quand vous donnez des droits à un modèle de langage.

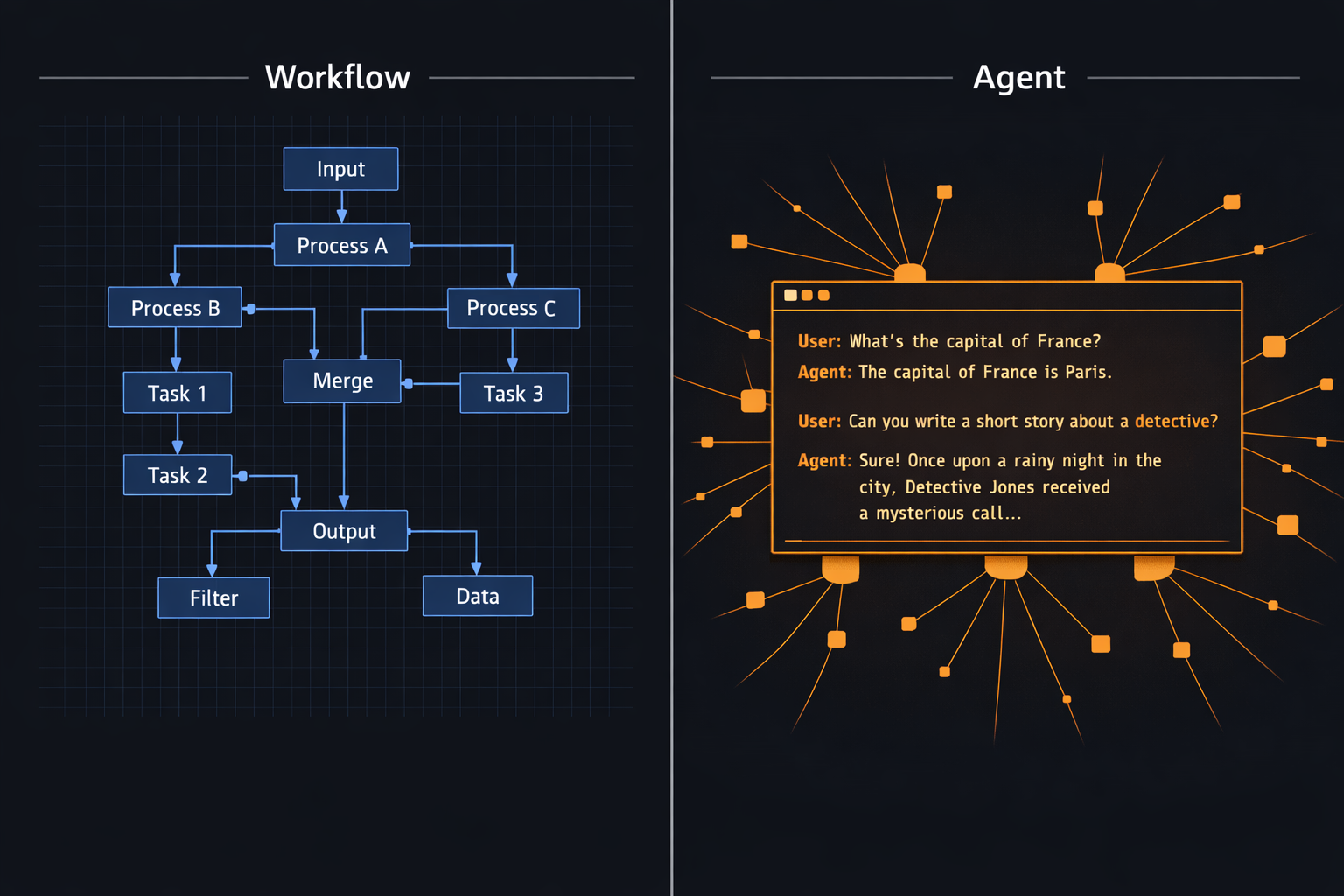
L'automatisation évolue depuis une décennie autour d'un paradigme clair : définir un workflow, connecter des briques, tester, déployer. Un noeud reçoit une entrée, applique une transformation, produit une sortie. Toujours la même. C'est la promesse de N8N, de Zapier, de Make. C'est aussi leur limite.
OpenClaw s'inscrit dans une autre logique : un agent LLM, hébergé sur votre infrastructure, capable de raisonner, d'agir sur des systèmes réels, et d'adapter sa réponse au contexte. La différence n'est pas seulement technique : elle change fondamentalement ce qu'il est possible d'automatiser, et ce qu'il est prudent de laisser faire.
N8N et OpenClaw : deux paradigmes d'automatisation
Le workflow déterministe
N8N repose sur un modèle contractuel : pour une entrée donnée dans un état donné, le résultat est identique et prévisible. C'est une propriété fondamentale pour les automatisations critiques. Un webhook reçoit une commande, un noeud HTTP appelle une API, un noeud Code formate la réponse, un noeud Slack envoie une notification. À chaque exécution, le même chemin.
Cette prévisibilité a un prix : la rigidité. Chaque cas non anticipé nécessite une branche supplémentaire. Une entrée ambiguë, un format inattendu, une condition à la limite du périmètre défini : le workflow s'arrête ou prend le mauvais chemin. L'ingénieur qui maintient le workflow doit avoir anticipé tous les états possibles.
N8N excelle dans les automatisations à fort volume, aux entrées formatées, aux règles métier stables. C'est l'outil adapté pour synchroniser un CRM avec un ERP, traiter des webhooks de paiement, ou orchestrer des pipelines ETL. Deux propriétés supplémentaires le rendent pertinent en environnement régulé : la traçabilité des échecs (quand un noeud échoue, le point de défaillance est immédiatement identifiable) et l'auditabilité native (chaque exécution est consignée, chaque étape est inspectable).
L'agent LLM orienté contexte
OpenClaw ne définit pas de workflow. Il expose des capacités à un modèle de langage (Claude par défaut), qui décide, à chaque interaction, quels outils utiliser et dans quel ordre. L'entrée peut être ambiguë, incomplète, en langage naturel. L'agent interprète, planifie, agit.
Cette architecture introduit une part de non-déterminisme. Deux requêtes identiques peuvent produire des réponses légèrement différentes selon le contexte de session, l'historique, ou les variations stochastiques du modèle. Ce comportement est inhérent aux LLM : la même phrase ne produit pas toujours le même token de sortie.
Ce n'est pas un défaut pour certaines classes de tâches. Synthétiser un état de veille, rédiger un draft adapté à un style éditorial, prendre une décision de routage à partir d'un email ambigu, ou orchestrer une séquence d'actions à partir d'une instruction en langage naturel : ce sont des cas où la flexibilité de l'agent dépasse structurellement ce qu'un workflow figé peut offrir.
Quand utiliser l'un ou l'autre
Les deux outils ne sont pas en concurrence frontale. N8N est adapté aux automatisations transactionnelles, répétables, à fort volume, où chaque case doit être cochée de la même façon à chaque exécution. OpenClaw est adapté aux tâches qui requièrent du jugement, de l'adaptation au contexte, ou une interaction en langage naturel. Les deux peuvent coexister dans une infrastructure : N8N gère les pipelines données, OpenClaw gère l'interface intelligente en couche au-dessus.
Ce qu'OpenClaw peut faire
Interface conversationnelle sur vos systèmes
La base d'OpenClaw est une gateway qui connecte un canal de messagerie (Telegram, Signal, Discord, iMessage...) à un agent LLM. L'agent dispose d'outils : lecture/écriture de fichiers, exécution de commandes shell, navigation web, appels HTTP. L'utilisateur interagit en langage naturel depuis son téléphone, l'agent agit sur le serveur.
Ce modèle ouvre des usages qui nécessitaient jusqu'ici une interface dédiée, une API personnalisée, ou une présence sur la machine : déclencher un déploiement depuis un message, récupérer l'état d'un service, générer un rapport à la demande, consulter ses emails ou son calendrier via la voix.
Scheduling et automatisation temporelle
OpenClaw intègre un moteur de cron natif. Il est possible de planifier des tâches récurrentes (rappels, checks périodiques, digests automatiques) directement depuis une conversation, sans toucher à un fichier crontab. Le déclenchement peut injecter un événement dans la session principale ou lancer un sous-agent isolé pour exécuter une tâche de fond.
Cette couche de scheduling combinée à la capacité de raisonnement de l'agent permet des automatisations conditionnelles que les crons classiques ne savent pas faire : « préviens-moi uniquement si le certificat expire dans moins de 10 jours », « envoie le digest uniquement si plus de 5 articles pertinents ont été collectés ».
Navigation web et collecte d'informations
L'agent peut accéder au web via deux mécanismes. Le premier est l'API Brave Search, configurée avec une clé API : recherche native, sans navigateur, faible latence. Le second est un navigateur Chromium headless, installé et configuré séparément en tant que service système, utile pour les pages JavaScript-heavy, l'interaction avec des formulaires, ou les captures d'écran. Les deux sont optionnels et complémentaires.
Combiné à des SKILLS, l'agent peut agréger, dédupliquer, scorer par pertinence avec le LLM, puis dispatcher le résultat vers vos outputs.
Gestion de fichiers et intégrations tierces
Les skills étendent les capacités de l'agent en exposant des scripts CLI que le modèle peut invoquer. N'importe quelle intégration packagée de cette façon devient accessible en langage naturel : CMS, stockage cloud, messagerie, outils de versioning, APIs métier. L'écosystème ClawHub propose des skills prêts à l'emploi, et le format est ouvert : un script Python avec une interface CLI suffit pour créer le sien.
L'agent orchestre ces capacités en raisonnant sur le contexte. Une instruction ambiguë ou multi-étapes déclenche une séquence d'appels coordonnée par le modèle, sans qu'aucun workflow n'ait été prédéfini.
Voix et accessibilité
OpenClaw supporte les messages vocaux entrants (transcription via Whisper.cpp) et la synthèse vocale sortante (TTS via OpenAI ou ElevenLabs). L'agent devient ainsi utilisable sans toucher un écran : question vocale depuis un téléphone, réponse audio. La latence reste dépendante du modèle et du matériel, mais le cas d'usage est fonctionnel sur une VM standard.
Surface d'attaque : ouvrir ses accès à un LLM
L'injection de prompt
Les LLM sont vulnérables aux injections de prompt : un contenu malveillant intégré dans une entrée traitée par le modèle peut modifier son comportement, lui faire ignorer ses instructions système, ou l'amener à exécuter des actions non prévues. Cette classe de vulnérabilité est documentée et active.
Dans le contexte d'un agent connecté à des systèmes réels, les conséquences sont concrètes. Un agent qui lit des emails pour les résumer peut être amené, si le modèle n'est pas robuste, à exécuter une instruction cachée dans un email entrant. Un agent qui scrape des pages web peut être détourné par un contenu spécialement conçu pour modifier son comportement.
Les contre-mesures disponibles sont imparfaites : isolation des sessions, validation des entrées avant injection dans le contexte, restrictions explicites dans le prompt système, revue humaine pour les actions sensibles. Aucune n'est infaillible. La sécurité par le prompt est une couche défensive parmi d'autres, pas un périmètre étanche.
Droits machine et principe de moindre privilège
OpenClaw s'exécute avec les droits de l'utilisateur système qui le lance. Si cet utilisateur a des droits étendus sur la machine (sudo sans mot de passe, accès à des répertoires sensibles, clés SSH), l'agent en hérite. Une compromission de l'agent devient une compromission de la machine.
Les bonnes pratiques sont identiques à celles de n'importe quel service exposé : utilisateur système dédié avec droits minimaux, séparation des secrets (vault ou fichiers chmod 600 hors du répertoire de l'application), accès réseau restreint. La différence avec un service classique est que l'agent peut, par conception, exécuter des commandes shell arbitraires si les outils le permettent. Ce périmètre doit être explicitement défini et restreint.
Un agent qui n'a pas besoin d'écrire dans `/etc` ne doit pas avoir accès à `/etc`. Un agent qui envoie des emails ne doit pas avoir de clé SSH vers des serveurs de production. Le principe de moindre privilège s'applique avec d'autant plus de rigueur que la surface de décision est déléguée à un modèle.
Les skills : puissance et surface d'exposition
Chaque skill installé étend les capacités de l'agent et sa surface d'attaque. Un skill Ghost donne à l'agent la capacité de créer et modifier des posts sur un CMS. Un skill mail-client lui donne accès à une boîte email. Un skill SSH lui donnerait accès à des machines distantes.
La gestion des droits au niveau skill est critique. Les skills OpenClaw bien conçus exposent des flags explicites (`allow_write`, `allow_delete`, `allow_publish`) avec des valeurs par défaut restrictives. L'activation d'une capacité doit être un acte délibéré, documenté, et limité au strict nécessaire.
L'origine des skills mérite également attention : un skill installé depuis une source non vérifiée est un vecteur d'exfiltration potentiel. Le code des skills s'exécute sur le serveur, avec les droits de l'agent. La revue du code avant installation n'est pas optionnelle.
En pratique, la posture recommandée est la suivante : commencer avec un périmètre minimal, activer les capacités une par une, maintenir un inventaire des accès accordés, et traiter chaque nouveau skill comme on traite un nouveau service dans une infrastructure.
Ce que vous pouvez faire : cas d'usage concrets
La question pratique n'est pas « N8N ou OpenClaw ? » mais « pour ce besoin précis, lequel est pertinent ? ».
Il est possible d'intégrer des noeuds LLM dans N8N (via OpenAI, Anthropic ou autres). Mais chaque appel reste un noeud figé avec un prompt statique : si le comportement attendu évolue ou si les entrées changent de format, c'est le pipeline qu'il faut modifier manuellement. La maintenance de l'orchestration reste à la charge de l'ingénieur. OpenClaw délègue cette orchestration au modèle lui-même.
Plutôt N8N
- Synchronisation CRM / ERP sur webhook : volume élevé, logique fixe, même chemin à chaque exécution
- Notification Slack sur événement Git : déterministe, pas de jugement requis
- Pipeline ETL : traitement de masse, reproductible, coût LLM non justifié
- Routage de formulaires : règles métier stables et prévisibles
- Emails transactionnels : template fixe, volume élevé
Plutôt OpenClaw
- Veille RSS avec scoring par pertinence : la notion de « pertinent » est contextuelle, le LLM juge mieux qu'une règle fixe
- Rédaction assistée depuis une instruction vocale : multi-étapes, langage naturel, pas de workflow prédéfinissable
- Alerte conditionnelle intelligente : « préviens-moi si c'est grave » requiert une interprétation, pas un seuil numérique
- Déclenchement d'actions depuis Telegram : interface conversationnelle, instructions ambiguës par nature
- Rapport de supervision à la demande : synthèse contextuelle, pas de template figé
Environnement de test vs production : une frontière à ne pas négliger
Tester OpenClaw sur une VM isolée, sans accès au réseau interne, avec un utilisateur dédié et des secrets factices, est une chose. Déployer le même agent sur le VLAN de production de son organisation en est une autre.
Le nombre de data breaches liés à des accès tiers mal maîtrisés, des tokens API exposés ou des services internes accessibles sans authentification forte justifie de traiter cette distinction avec sérieux. Un agent LLM connecté à la messagerie interne, aux serveurs de fichiers et aux outils de déploiement d'une organisation représente une surface d'attaque significative. Une clé API volée, un prompt injection réussi ou un skill mal configuré peuvent avoir des conséquences concrètes sur des systèmes réels.
La recommandation n'est pas de ne pas déployer, mais de progresser par paliers : environnement sandbox d'abord, périmètre réseau restreint, audit des accès accordés à chaque étape, et validation explicite avant toute extension vers des systèmes critiques. Ce que vous ne connectez pas ne peut pas être compromis.
Sources




